分块方式
one
一个文件只生成一个 chunk,适合短文档、合同
book
针对长篇书籍(尤其是 PDF 格式),通过文本特征检测分割点,
chunk粒度与“ARTICLE(文章/章节)”一致,且包含所有上层文本。可设置“页面范围”,过滤无用内容,减少分析计算时间。
laws
利用法律文件“严格的格式特点”,通过文本特征检测分割点,
chunk粒度与“ARTICLE”一致,确保法律条文的结构完整性(所有上层文本会包含在chunk中)
paper
按论文的结构(如摘要、1.1 节、1.2 节等章节)切片。
优点:大语言模型(LLM)能更好概括章节内容,生成更全面的答案。
缺点:会增加 LLM 对话的上下文量与计算成本,可通过降低“topN(返回的相关块数量)”优化。
manual
假设文档有分层章节结构,同一章节内的图、表不会被分割,块大小可能较大。
适用场景:章节结构清晰、内容关联紧密的手册类文档(需注意:大章节会消耗更多 Token,可能影响检索精准度)。
presentation
PPTX 会提取每页文本 + 缩略图,生成一个 chunk;
PDF 版会按页码切割,每页独立成块;
保留页码信息,方便检索后定位原文件位置。
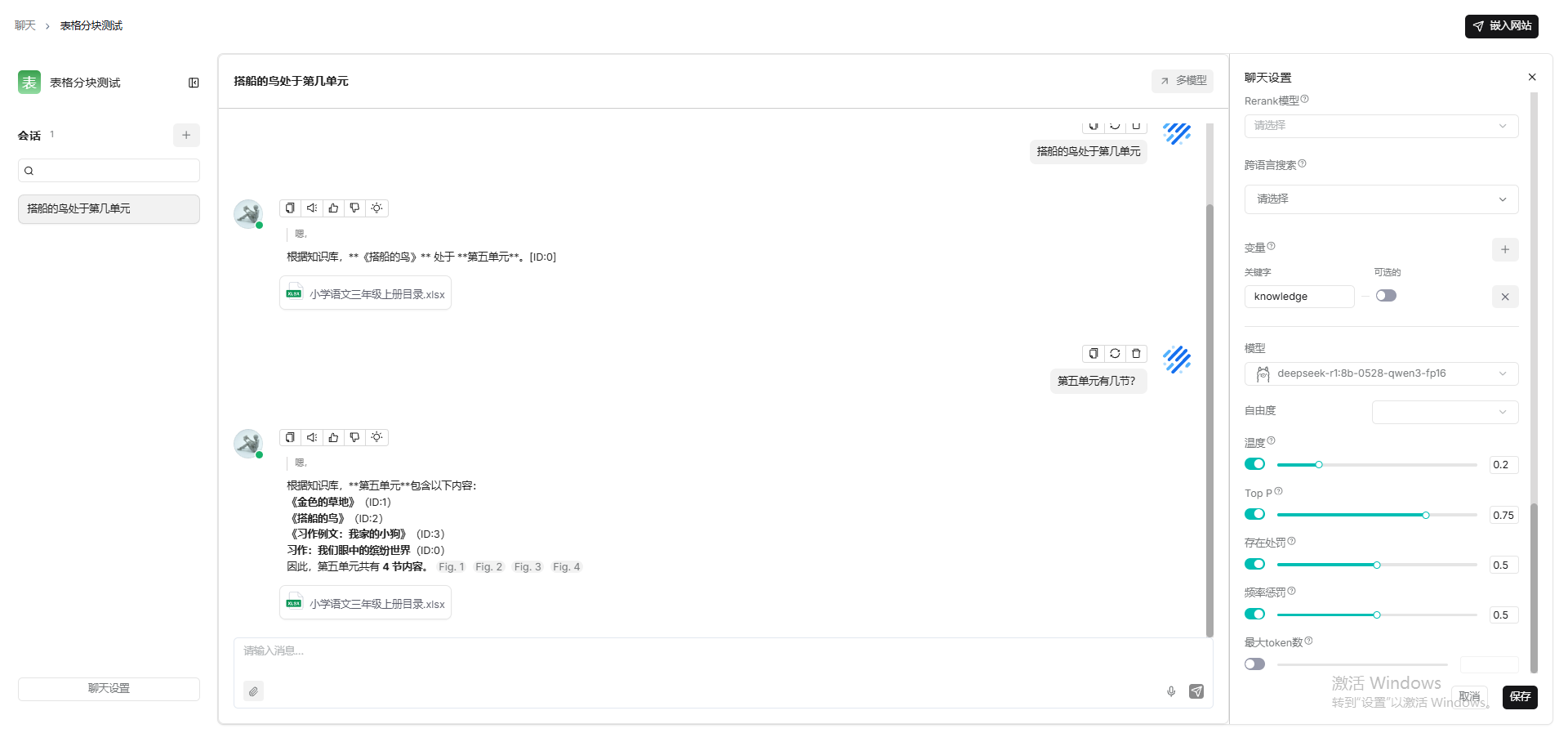
table
利用表格的“结构化特性”,将每行视为独立块。
qa
专为“问答对”类数据设计,每行“问题 - 答案”作为独立块。
Excel:需包含两列(无标题),第一列是问题、第二列是答案。
CSV/TXT:需用
UTF-8编码,且以 TAB 作为问题与答案的分隔符;不符合规则的行会被忽略。
tag
要求两列结构:一列内容,一列标签(支持多标签,用逗号分隔);
为知识库的块“添加标签”,其他知识库可基于这些标签关联块;对带标签的块进行查询时,也会携带标签信息。
用于多知识库间的“标签关联检索”,强化知识的关联性。
resume
不做“分块”,而是将简历解析为结构化数据(如提取学历、工作经历等字段)。
general
基本分块方法,首先利用视觉检测模型对文档进行文本布局分析,将连续文本分割成逻辑片段,然后将这些片段合并成token数量不超过预设阈值的块,以平衡上下文完整性和处理效率。
分块结果
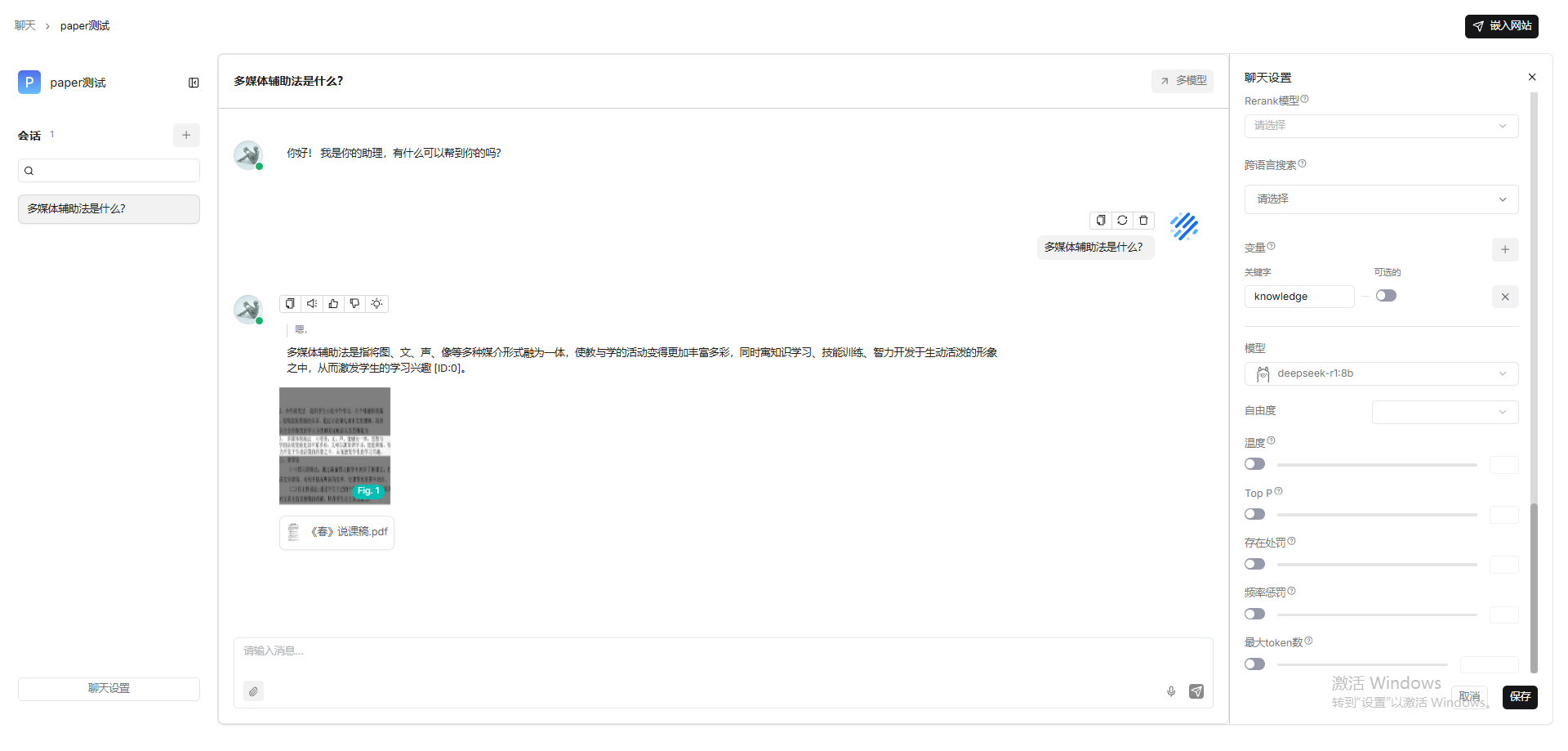
general(512)
教案-9,说课稿-6
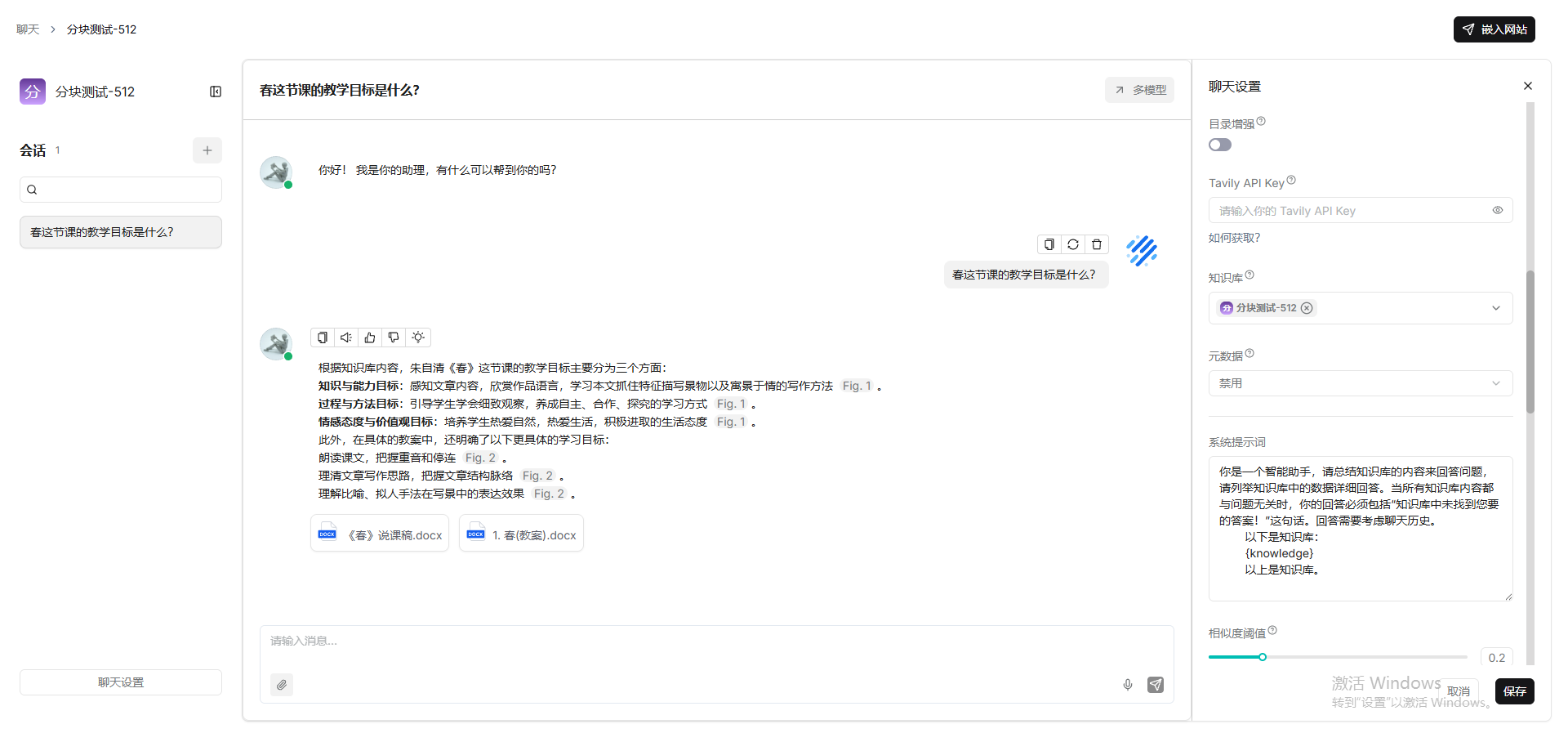
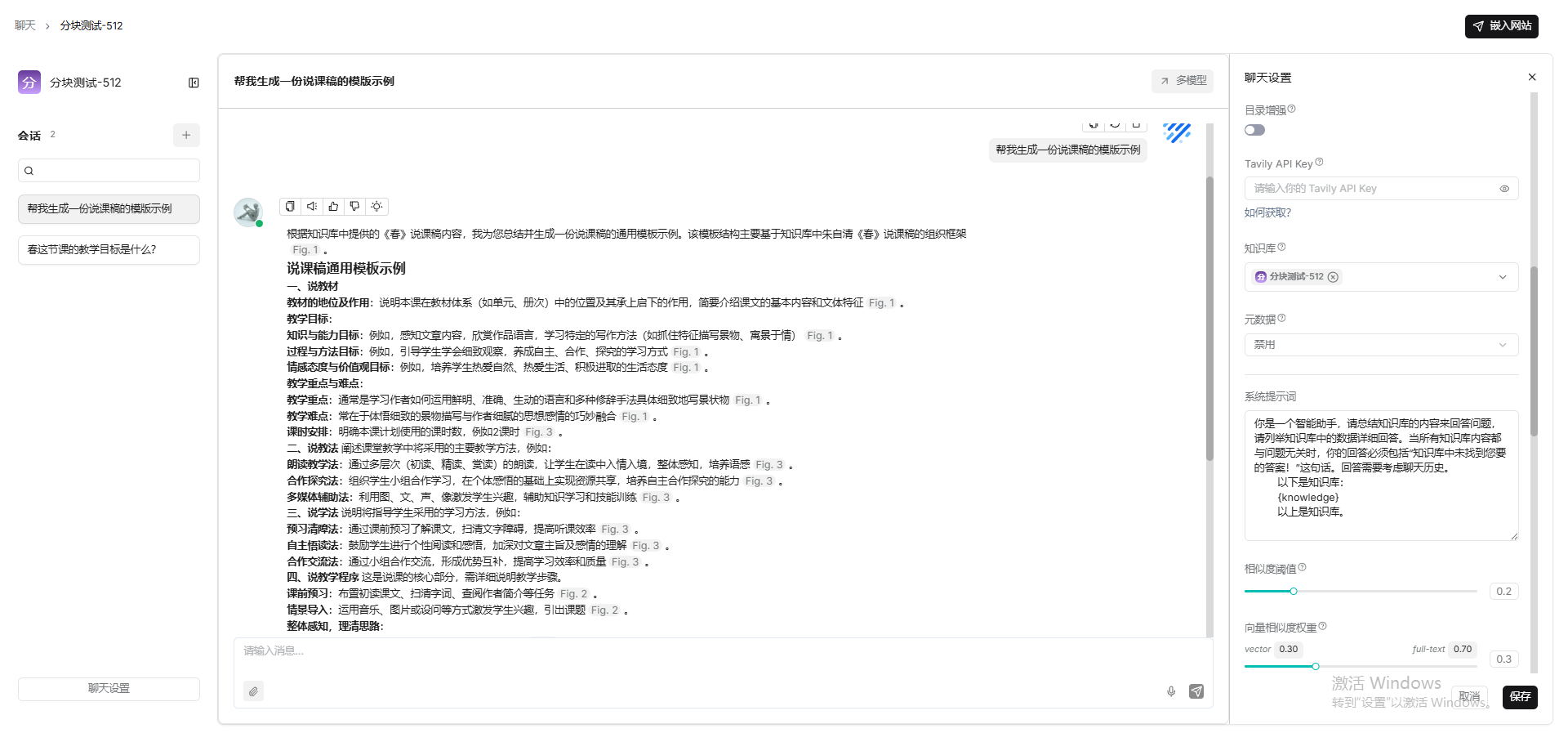
general(256)
教案-15,说课稿-12
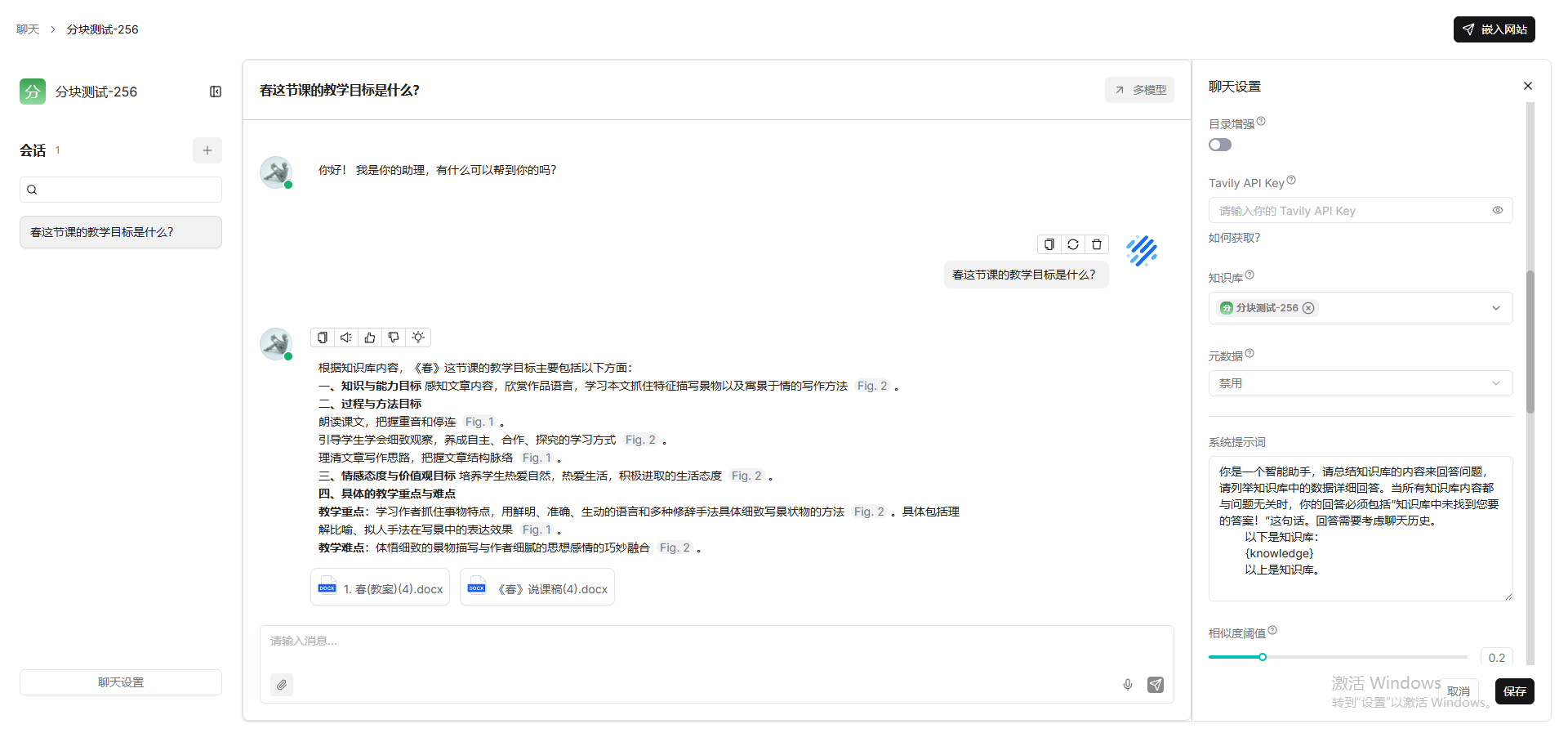
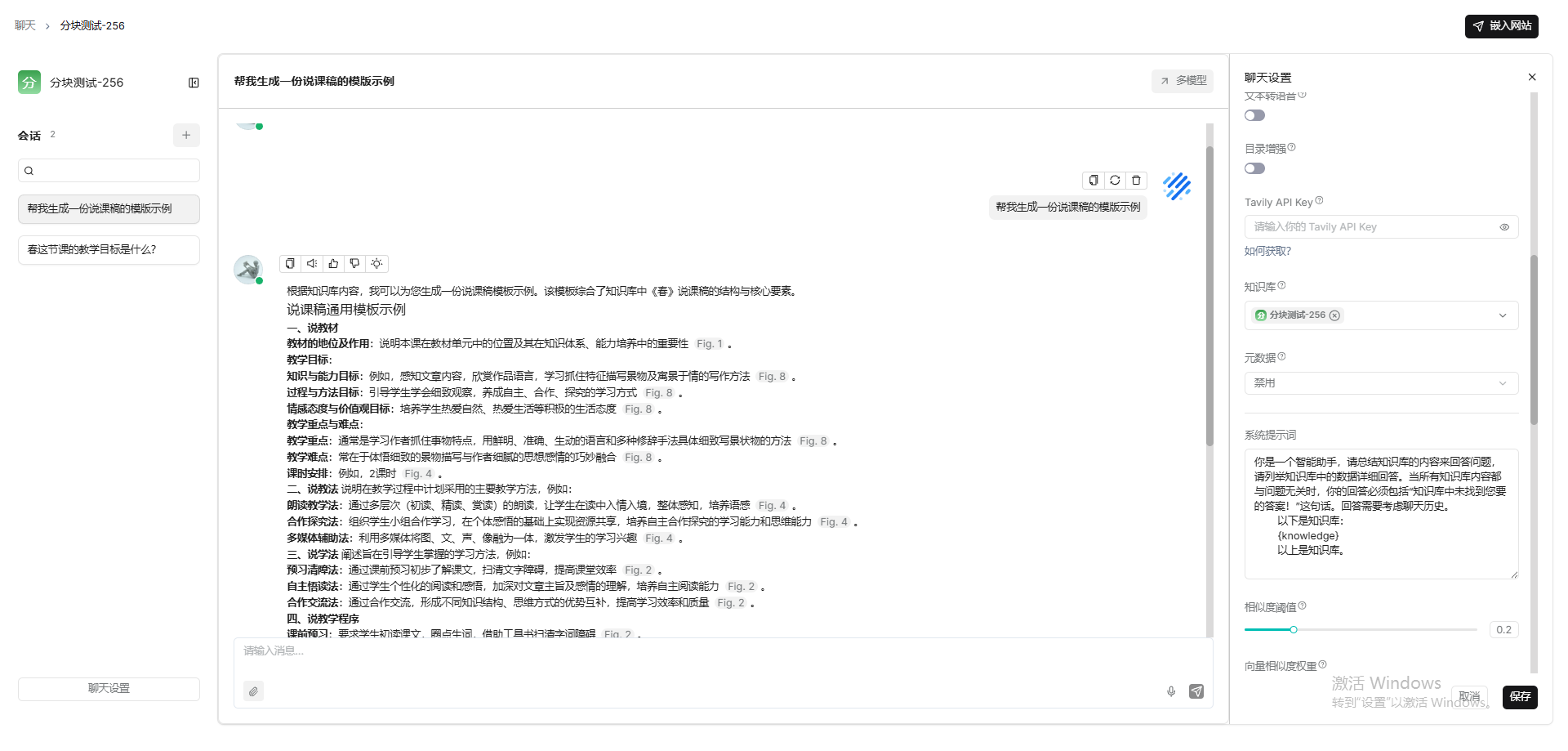
general(128)
教案-25,说课稿-20
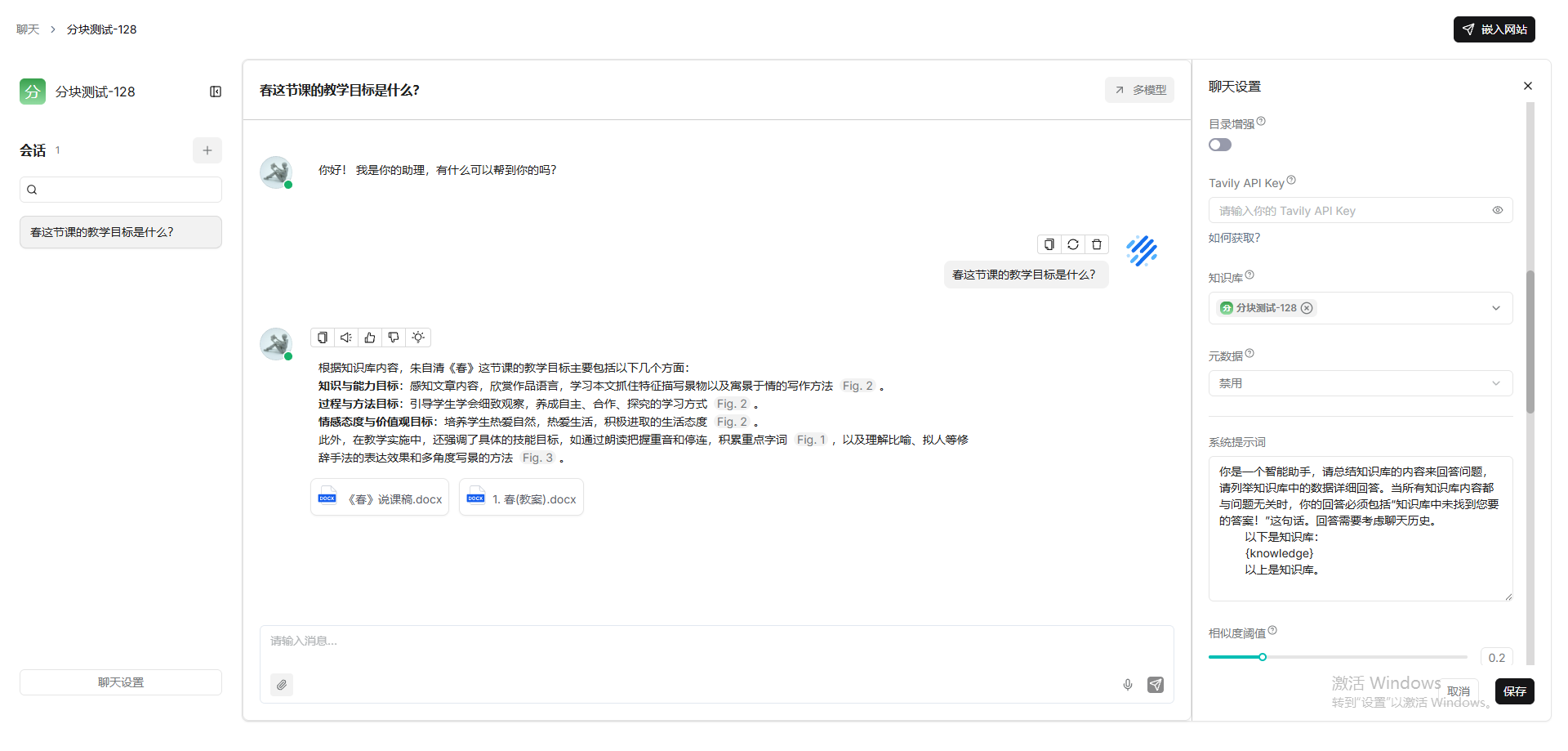
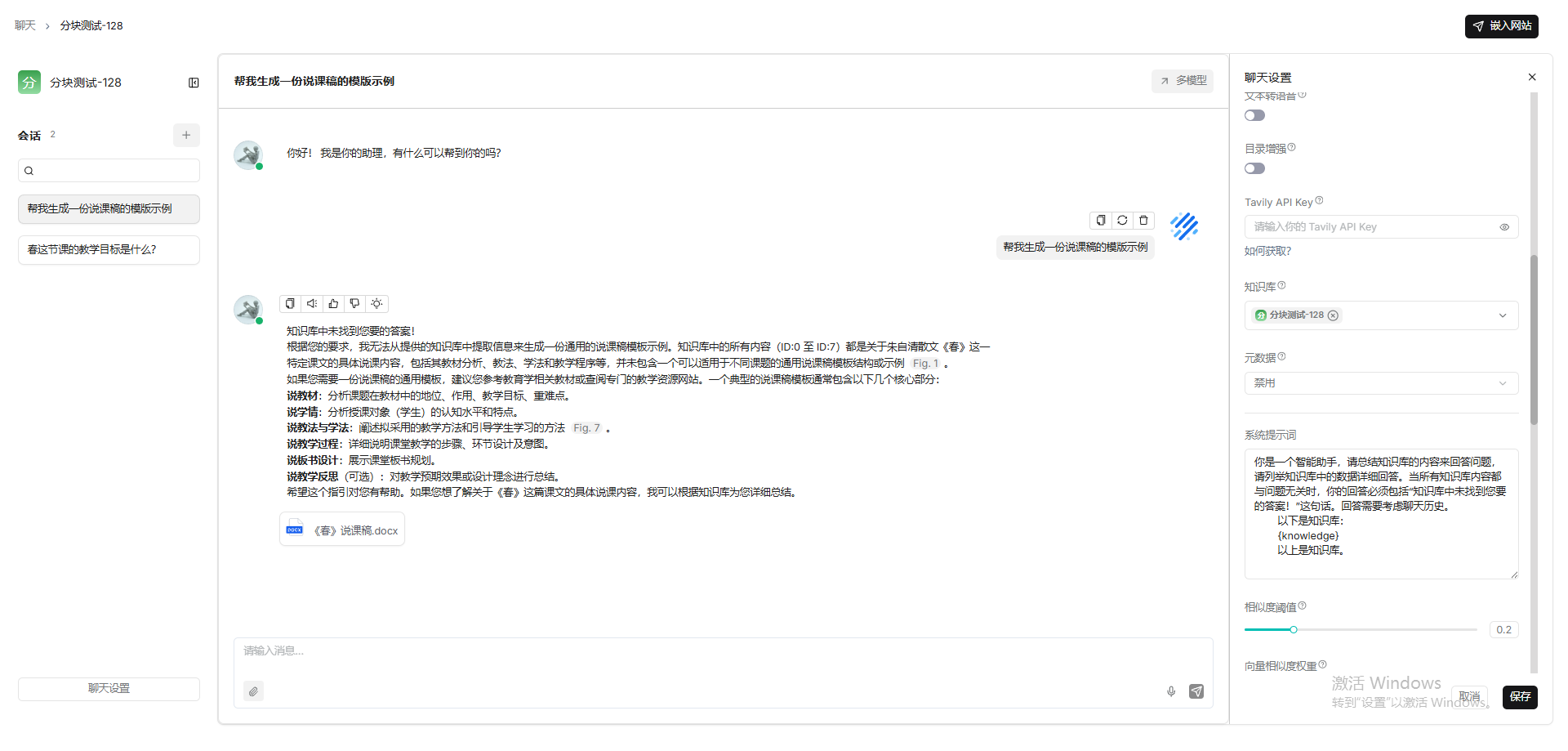
结论:不是分块的文本块大小越小越好,512效果要优于256、128.
PPT课件解析分块会自动使用presentation方法,每页一个块,包括截图和文本。
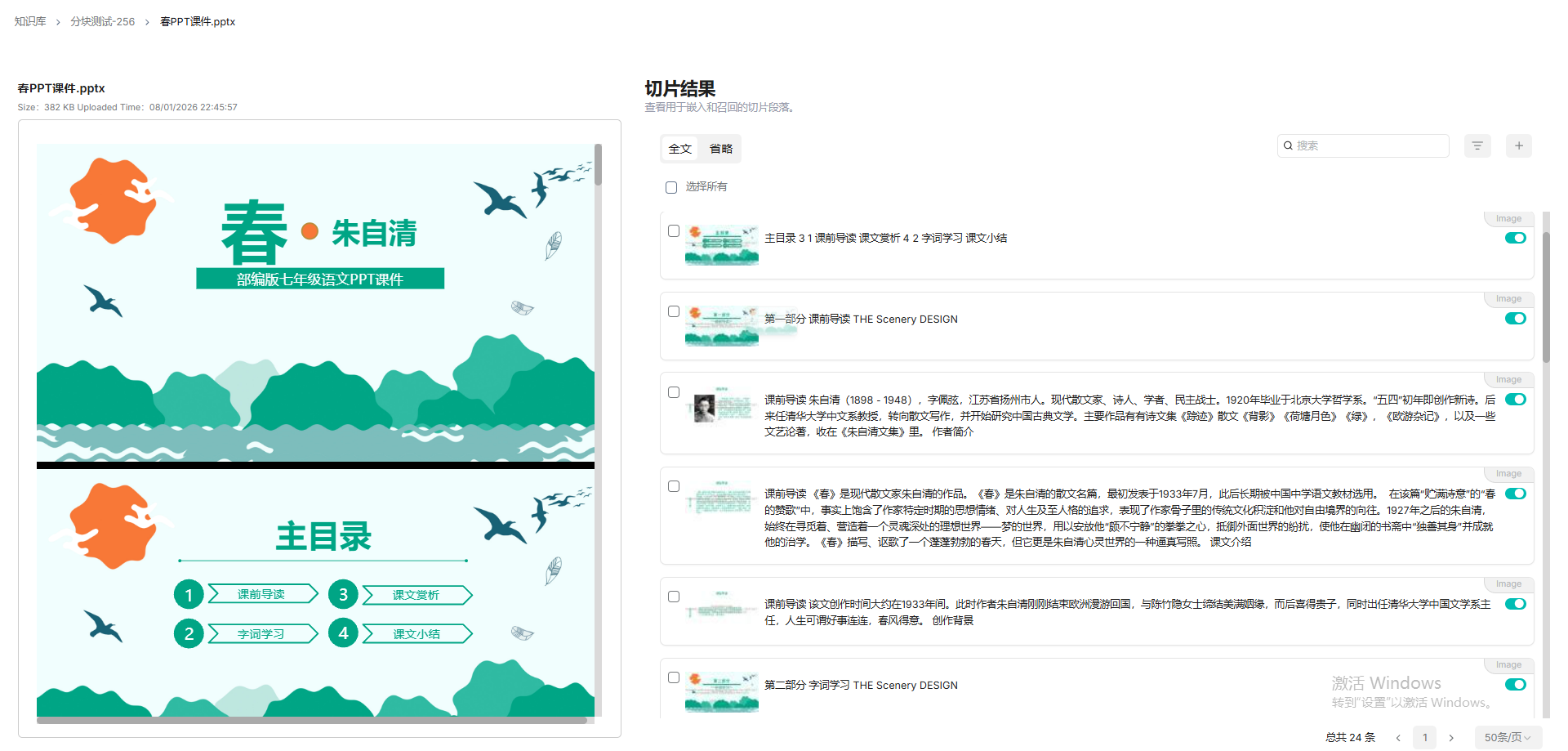
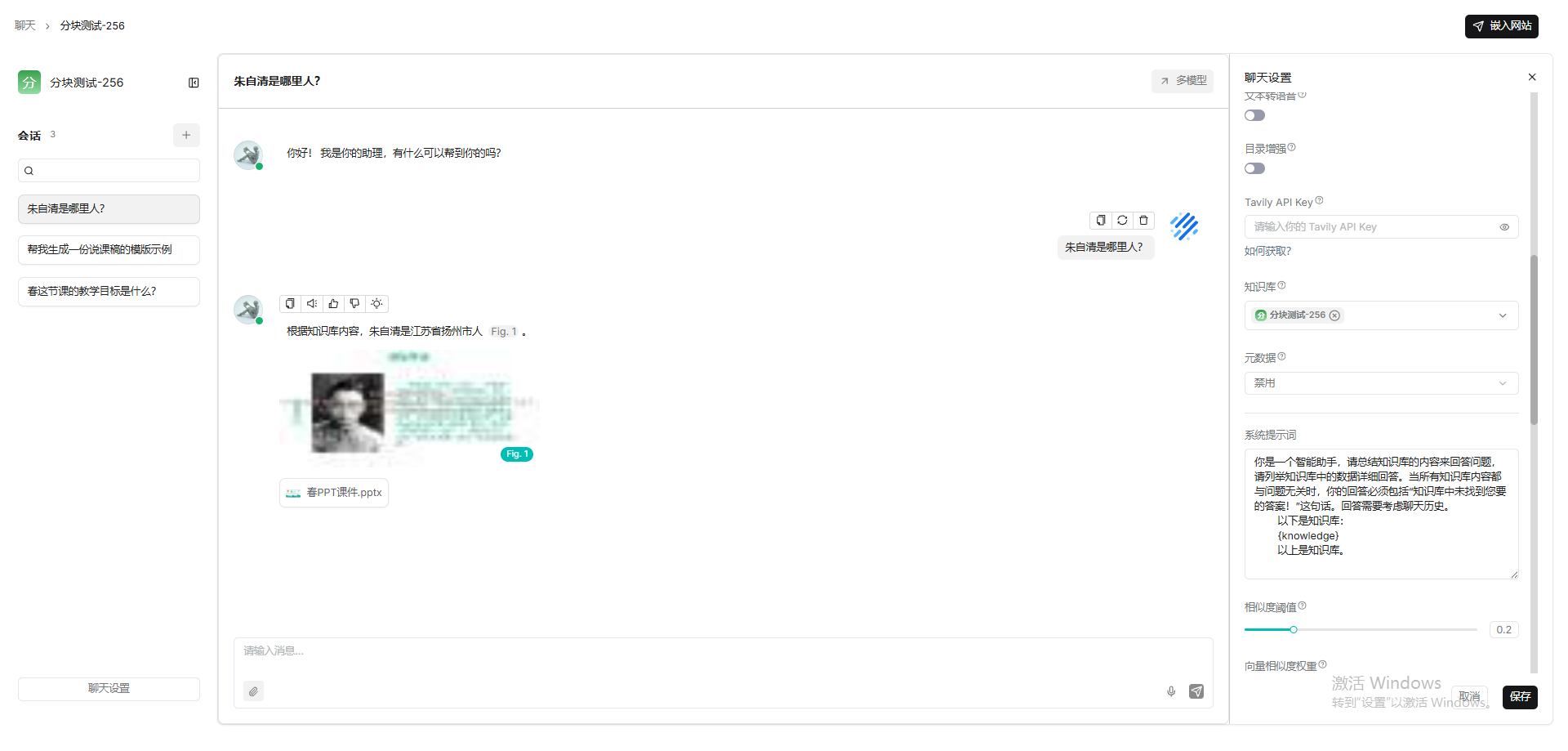
Excel文件解析要使用table方法,每行一个块(第一行必须是列标题,列标题必须是有意义的术语,以便我们的大语言模型能够理解。)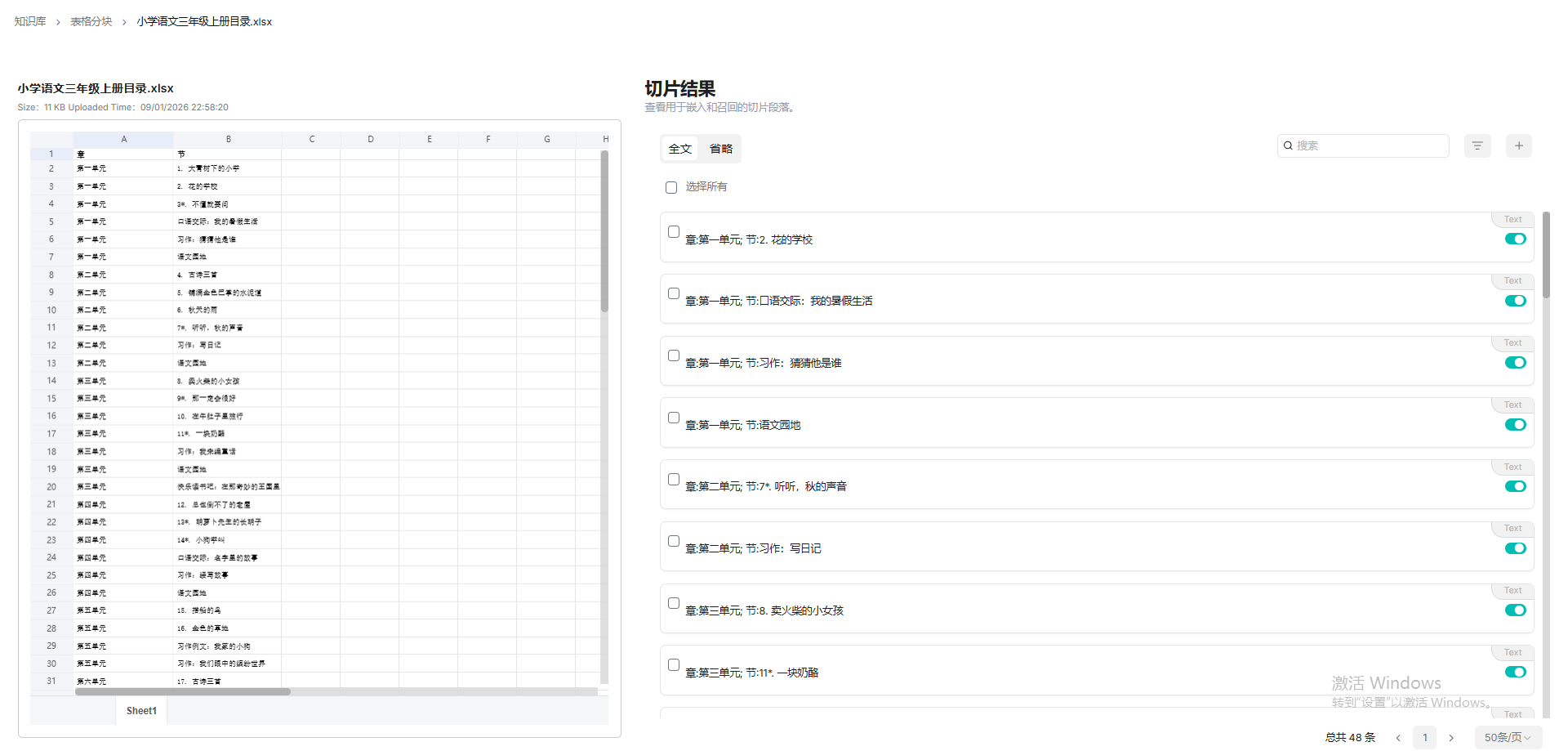
book方法,自动判断,段落分块(解析过程缓慢,检索回答效果不理想)。
paper方法,仅支持PDF文件,按照大、小标题切片。